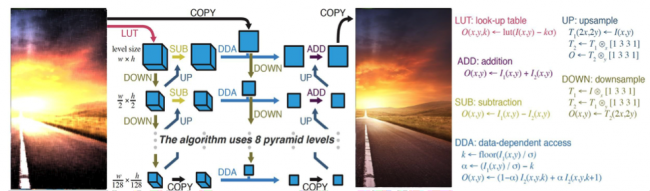
Perception is a critical component of autonomous and assisted driving. Enormous amounts of data from cameras and other optical sensors (e.g. Lidar) need to be processed in real time and with as low a latency as possible to allow cars not only to locate themselves, but also to react in a fraction of a second to unexpected situations. Reaching this level of performance has traditionally been a struggle with large implementation costs. Taking full advantage of modern processing units requires large implementation effort to extract parallelism (multicore, vectorization, GPU threads) and leverage the cache hierarchy. At best it takes substantial implementation time and resources from robotics researchers and practitioners, at worst it leads to significantly sub-optimal performance. The two orders of magnitude between a direct implementation and a highly optimized one can mean the difference between a perception system that runs at 10Hz vs. 1000Hz. In robotics in general, and in high-stakes situations such as intelligent autonomous or assisted driving in particular, it is well accepted that the speed and latency of the control loop are critical to robustness. This work can dramatically facilitate high-performance perception code, with huge potential payoffs for research in robotic vehicle.
We plan to introduce the Halide programming language as the base language for developing all of the image processing and most of the computer vision algorithms needed in autonomous and assisted driving. Image processing and computer vision pipelines combine the challenges of stencil computations and stream programs. They are composed of large graphs of different stencil stages, as well as complex reductions, sampling, feature recognition and stages with global or data-dependent access patterns. Halide enables practitioners to write much simpler and modular programs. Halide decouples the algorithm, which describes the computation, from the schedule which describes when, where and how to perform that computation. Thus, the programmers can write the algorithm once and easily iterate over different complex graph assemblies until they find the best optimization. Halide is shown to deliver performance often an oder of magnitude faster than the best prior hand-tuned C, assembly, and CUDA implementations of image processing pipelines. Halide programs are also portable across radically different architectures, from ARM mobile processors to massively parallel GPUs, by making changes only to the schedule, while traditionally-optimized implementations are highly specific to a single target architecture. They are also modular and composable, where traditional implementations have to fuse many operations into a monolithic whole for performance. Thus, we belive that moving an optimized image-vision pipeline from a vehicle simulator to an actual vehicle for testing or production will be fast and simple.
Check the Tensor Algebra Compiler (taco).
This is a continuation of the project "Drinking from the Visual Firehose: High-Frame-Rate, High-Resolution Computer Vision for Autonomous and Assisted Driving" by Saman Amarasinghe, Fredo Durand, John Leonard.
Publications:
- S. Chou, F. Kjolstad, and S. Amarasinghe, “Automatic generation of efficient sparse tensor format conversion routines,” in Proceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation, London UK, 2020, pp. 823–838, doi: 10.1145/3385412.3385963 [Online]. Available: https://doi-org.ezproxy.canberra.edu.au/10.1145/3385412.3385963
- A. Adams, F. Durand, J. Ragan-Kelley, K. Ma, L. Anderson, R. Baghdadi, T.-M. Li, M. Gharbi, B. Steiner, S. Johnson, and K. Fatahalian, “Learning to optimize halide with tree search and random programs,” ACM Transactions on Graphics, vol. 38, no. 4, pp. 1–12, Jul. 2019 [Online]. Available: https://doi-org.ezproxy.canberra.edu.au/10.1145/3306346.3322967
- Y. Hu, T.-M. Li, L. Anderson, J. Ragan-Kelley, and F. Durand, “Taichi: a language for high-performance computation on spatially sparse data structures,” ACM Trans. Graph., vol. 38, no. 6, pp. 1–16, Nov. 2019, doi: 10.1145/3355089.3356506. [Online]. Available: https://doi-org.ezproxy.canberra.edu.au/10.1145/3355089.3356506
- F. Kjolstad, P. Ahrens, S. Kamil, and S. Amarasinghe, “Tensor Algebra Compilation with Workspaces,” in Proceedings of the 2019 IEEE/ACM International Symposium on Code Generation and Optimization, 2019 [Online]. Available: https://dl-acm-org.ezproxy.canberra.edu.au/doi/10.5555/3314872.3314894
- Z. Jia, A. Zlateski, F. Durand, and K. Li, “Optimizing N-Dimensional,Winograd-Based Convolution for Manycore CPUs,” in Principles and Practice of Parallel Programming 2018 (PPoPP 2018), Vösendorf / Wien, Austria, 2018 [Online]. Available: https://doi-org.ezproxy.canberra.edu.au/10.1145/3178487.3178496
- A. Zlateski, Z. Jia, K. Li, and F. Durand, “A Deeper Look at FFT and Winograd Convolutions,” in SysML Conference, Stanford, CA, 2018 [Online]. Available: http://www.sysml.cc/doc/28.pdf
- Z. Jia, A. Zlateski, F. Durand, and K. Li, “Towards Optimal Winograd Convolution on Manycores,” in SysML Conference, Stanford, CA, 2018 [Online]. Available: http://www.sysml.cc/doc/47.pdf
- S. Chou, F. Kjolstad, and S. Amarasinghe, “Format Abstraction for Sparse Tensor Algebra Compilers,” presented at the International Conference on Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA 2018), 2018, vol. 2 [Online]. Available: https://doi-org.ezproxy.canberra.edu.au/10.1145/3276493
- F. Kjolstad, S. Kamil, S. Chou, D. Lugato, and S. Amarasinghe, “The tensor algebra compiler,” Proceedings of the ACM on Programming Languages, vol. 1, no. OOPSLA, pp. 1–29, Oct. 2017 [Online]. Available: https://doi-org.ezproxy.canberra.edu.au/10.1145/3133901.
News:
Videos: