Language is our primary means of communication, and speech is one of its most convenient and efficient means of conveyance. Due to our ability to communicate by voice in hands-busy, eyes-busy environments, spoken interaction in the vehicle environment will become increasingly prevalent as cars become more intelligent, and are continuously perceiving (e.g., `listening' and `seeing') their environment. More generally, as humans and cognitive machines interact, it will be important for both parties to be able to speak with each other about things that they perceive in their local environment. This project explores deep learning methods to create models that can automatically learn correspondences between things that a machine can perceive, and how people talk about them in ordinary spoken language. The current project has successfully developed models with an ability to learn semantic relationships between objects in images and their corresponding spoken form. The results of this research should have wide-scale applications to future cognitive vehicles and other cognitive machines that operate in same physical environment as humans.
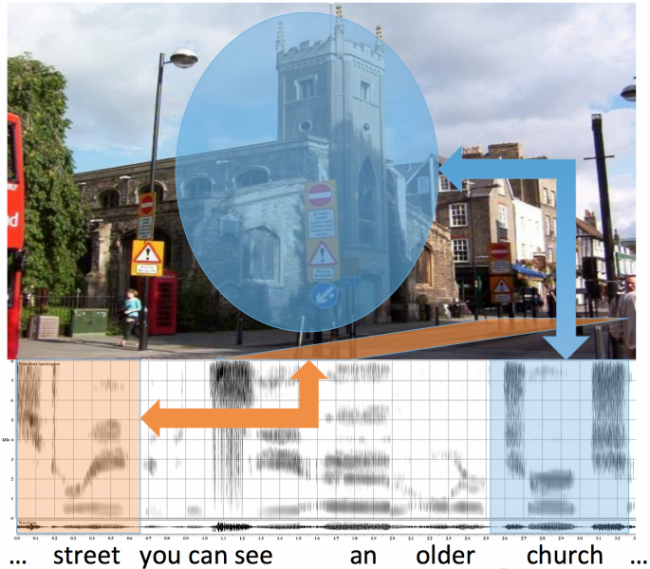
Our recent research [Harwath et al., NIPS 2016; Harwath et al., ACL 2017; Leidel et al., ASRU 2017], investigates deep learning methods for learning semantic concepts across both audio and visual modalities. Contextually correlated streams of sensor data from multiple modalities - in this case a visual image accompanied by a spoken audio caption describing that image - are used to train networks capable of discovering patterns using otherwise unlabeled training data. For example, these networks are able to pick out instances of the spoken word ``water" from within continuous speech signals and associate them with images containing bodies of water. The networks learn these associations directly from the data, without the use of conventional speech recognition, text transcriptions, or any expert linguistic knowledge whatsoever.
We have been using the MIT Places image corpus, augmented with spoken descriptions of the images that we have collected via crowdsourcing, to learn a multi-modal embedding space using a neural network architecture. We have explored several different models, and have been quantifying the performance of these models in image search and annotation retrieval tasks, where, given an image or a spoken image description, the task is to find the matching pair out of a set of 1000 candidates. Currently we are able to achieve similar results to other models that have been trained on text captions, even though our models are only provided with unannotated audio signals. Thus, they could potentially operate on any spoken language in the world, without needing any additional annotation.
In ongoing work, we are planning to extend these models to video, include an audio channel, and explore datasets that are more focused on particular semantic concepts that are relevant for driving or interacting with robots.
This is a continuation of the project "Crossing the Vision-Language Boundary for Contextual Human-Vehicle Interaction".
Publications:
- F. Grondin, H. Tang, and J. Glass, “Audio-Visual Calibration with Polynomial Regression for 2-D Projection Using SVD-PHAT,” in ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 2020, pp. 4856–4860, doi: 10.1109/ICASSP40776.2020.9054690[Online]. Available: https://doi-org.ezproxy.canberra.edu.au/10.1109/ICASSP40776.2020.9054690
- D. Harwath, W.-N. Hsu, and J. Glass, “LEARNING HIERARCHICAL DISCRETE LINGUISTIC UNITS FROM VISUALLY-GROUNDED SPEECH,” in ICLR 2020, 2020 [Online]. Available: https://iclr.cc/virtual_2020/poster_B1elCp4KwH.html
- F. Grondin and J. Glass, “Fast and Robust 3-D Sound Source Localization with DSVD-PHAT,” in 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 2019, pp. 5352–5357, doi: 10.1109/IROS40897.2019.8967690 [Online]. Available: https://doi-org.ezproxy.canberra.edu.au/10.1109/IROS40897.2019.8967690
- F. Grondin and J. Glass, “Multiple Sound Source Localization with SVD-PHAT,” in Interspeech 2019, 2019, pp. 2698–2702, doi: 10.21437/Interspeech.2019-2653[Online]. Available: http://www.isca-speech.org/archive/Interspeech_2019/abstracts/2653.html
- D. Harwath, A. Recasens, D. Surıs, G. Chuang, A. Torralba, and J. Glass, “Jointly Discovering Visual Objects and Spoken Words from Raw Sensory Input,” International Journal of Computer Vision, Aug. 2019 [Online]. Available: https://doi-org.ezproxy.canberra.edu.au/10.1007/s11263-019-01205-0
- D. Suris, A. Recasens, D. Bau, D. Harwath, J. Glass, and A. Torralba, “Learning Words by Drawing Images,” in CVPR 2019, 2019 [Online]. Available: http://openaccess.thecvf.com/content_CVPR_2019/papers/Suris_Learning_Words_by_Drawing_Images_CVPR_2019_paper.pdf
- F. Grondin and J. Glass, “SVD-PHAT: A FAST SOUND SOURCE LOCALIZATION METHOD,” in 44th International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2019, 2019 [Online]. Available: https://doi-org.ezproxy.canberra.edu.au/10.1109/ICASSP.2019.8683253
- D. Harwath, A. Recasens, D. Surís, G. Chuang, A. Torralba, and J. Glass, “Jointly Discovering Visual Objects and Spoken Words from Raw Sensory Input,” in ECCV 2018, Cham, 2018, vol. 11210, pp. 659–677 [Online]. Available: https://doi-org.ezproxy.canberra.edu.au/10.1007/978-3-030-01231-1_40
- D. Harwath, G. Chuang, and J. Glass, “Vision as an Interlingua: Learning Multilingual Semantic Embeddings of Untranscribed Speech,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 4969–4973 [Online]. Available: https://doi-org.ezproxy.canberra.edu.au/10.1109/ICASSP.2018.8462396
- K. Leidal, D. Harwath, and J. Glass, “Learning Modality-Invariant Representations for Speech and Images,” in 2017 IEEE Automatic Speech Recognition and Understanding Workshop, Okinawa, Japan, 2017 [Online]. Available: https://asru2017.org/Papers/ViewPapers.asp?PaperNum=1259
- D. Harwath and J. Glass, “Learning Word-Like Units from Joint Audio-Visual Analysis,” in The 55th Annual Meeting of the Association for Computational Linguistics, 2017, pp. 506–517 [Online]. Available: https://doi-org.ezproxy.canberra.edu.au/10.18653/v1/P17-1047
- D. Harwath, A. Torralba, and J. Glass, “Unsupervised learning of spoken language with visual context,” in Advances in Neural Information Processing Systems, Barcelona, Spain, 2016 [Online]. Available: https://papers.nips.cc/paper/6186-unsupervised-learning-of-spoken-language-with-visual-context.pdf
Videos: